

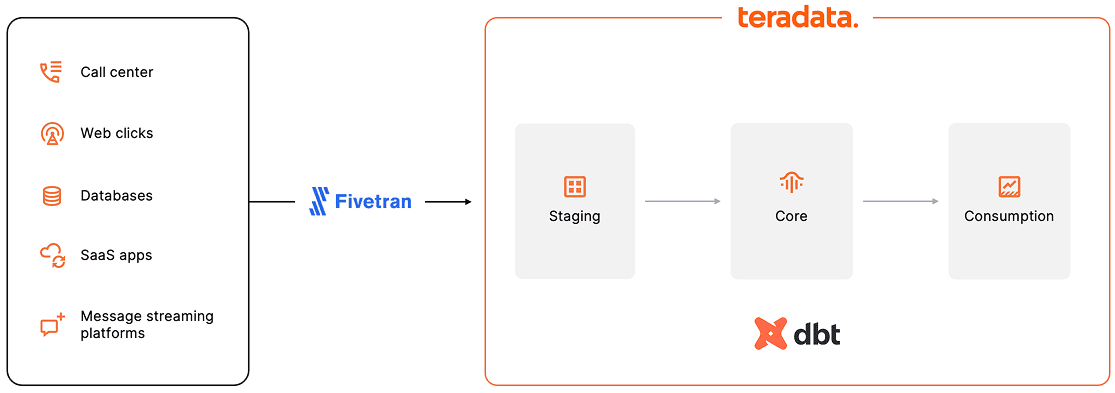
Teradata is committed to building an open and connected ecosystem. To bring this vision to life, Teradata has developed a robust network of partnerships across the modern data stack, spanning both the open-source and commercial landscapes. As part of this growing network, we recently announced a partnership with Fivetran, the global leader in data movement.
This integration enables interesting possibilities—for example, you can build a fully managed end-to-end data pipeline that is, in essence, very low code. Here's a simple pipeline to get you thinking about the possibilities.
The use case
We'll build a simple data pipeline in which we’ll manage data extraction, loading, and transformation through the managed services provided by Fivetran and dbt Cloud. This means the data extraction and loading are scheduled, and the transformation follows next, in one place and on one schedule in Fivetran.
The data used for this data pipeline is a simple, retailer-like dataset that we ingest and transform through a dbt Cloud project. This article focuses on the pipeline itself, so we don’t describe the dbt models in detail. You can find those details in the readme file of the corresponding repository.
Requirements
To build your own version of this pipeline, you’ll need:
- A Fivetran account
- Fivetran offers a free trial for 14 days after signing up
- A dbt Cloud account
- A free trial is offered for 14 days after signing up
- A Teradata Vantage™ instance
- A Google Drive account
Loading testing data in the source
- Download the testing source data here. The data is in three spreadsheets due to the convenience of this type of source, which doesn’t require describing complex schemas—making it suitable for this type of article.
- Upload the spreadsheets to a folder in your Google Drive account.
Setting the required services
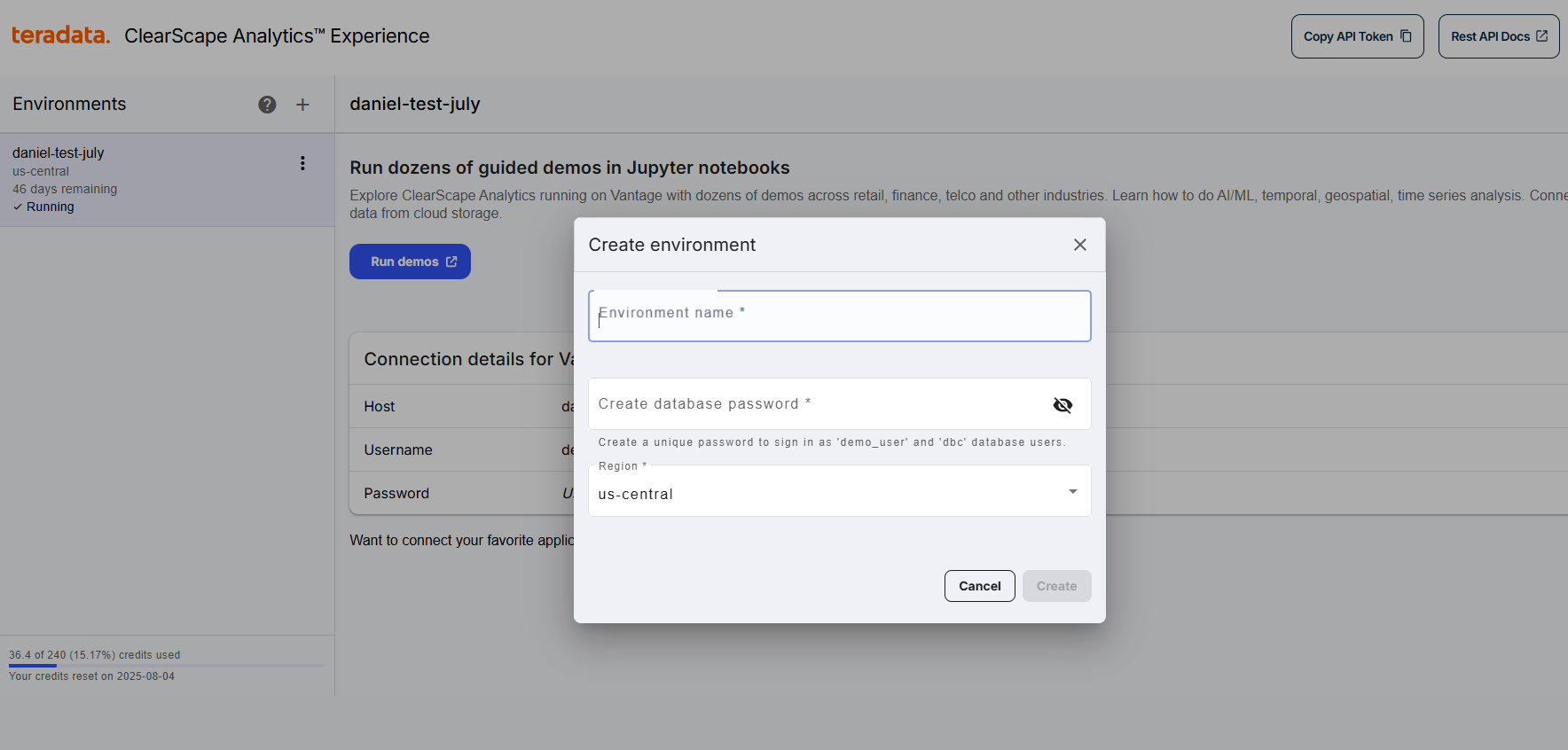
Secure a Teradata Vantage™ instance through ClearScape Analytics® Experience:
- Log in to ClearScape Analytics® Experience
- Create an environment in the console (note your password, as you’ll need it to interact with the database)
dbt Cloud
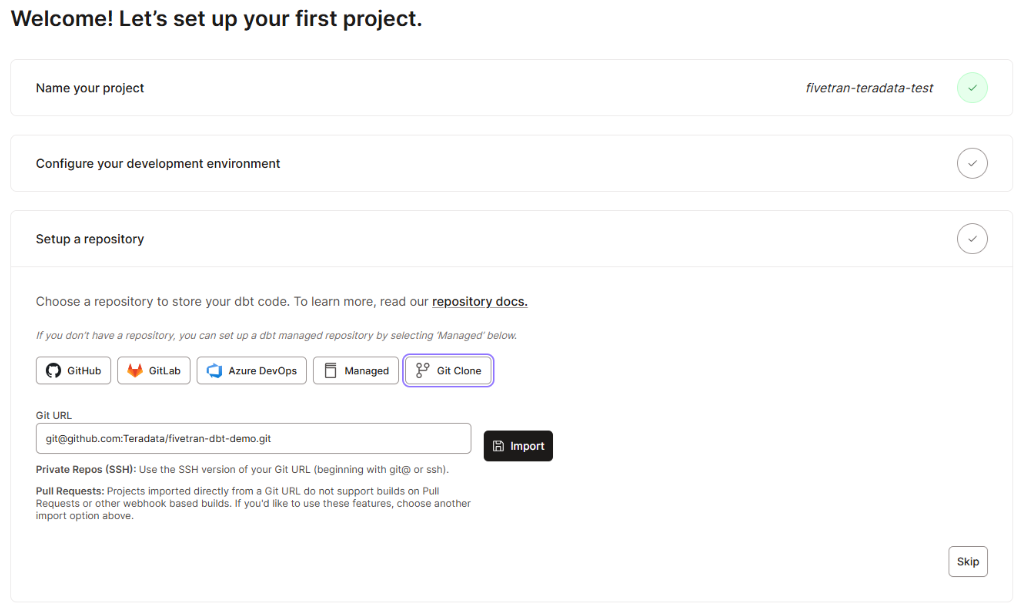
- Log in to your dbt Cloud account
- Follow our guide to set a dbt Cloud project:
- For the connection, choose your corresponding ClearScape Analytics® Experience environment credentials
- Choose Git clone as the integration method of the required git repository
- Set
git@github.com:Teradata/fivetran-dbt-demo.gitas the git URL (this is the SSH form of the Teradata/fivetran-dbt-demo demo repository) - You can also clone the sample repository in your own account and modify it to experiment further
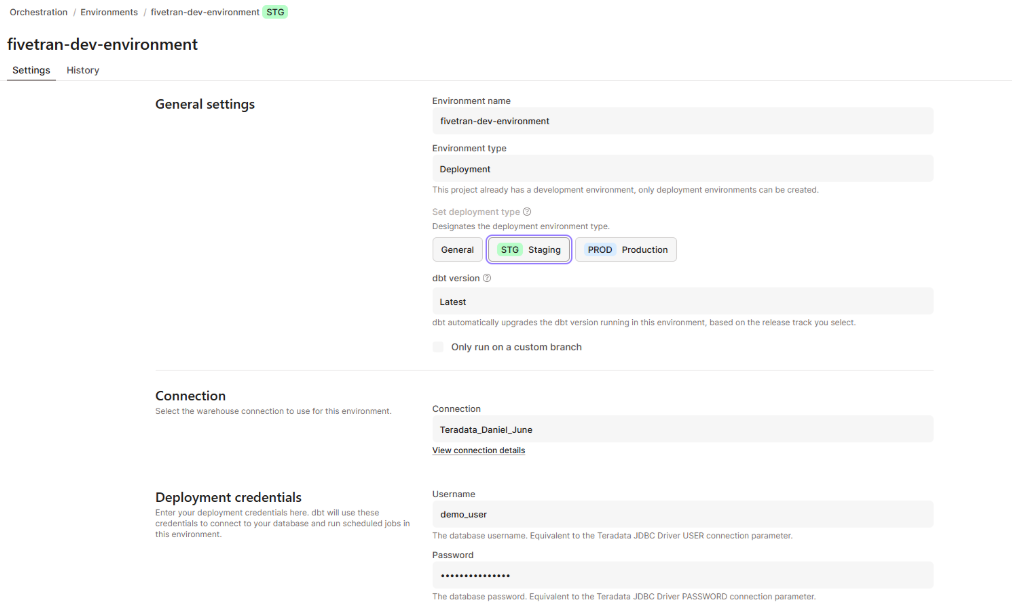
- Create a deployment environment in dbt Cloud
- Set your ClearScape Analytics® Experience environment credentials in this environment
- Once your project is created, create a job on top of your deployment environment
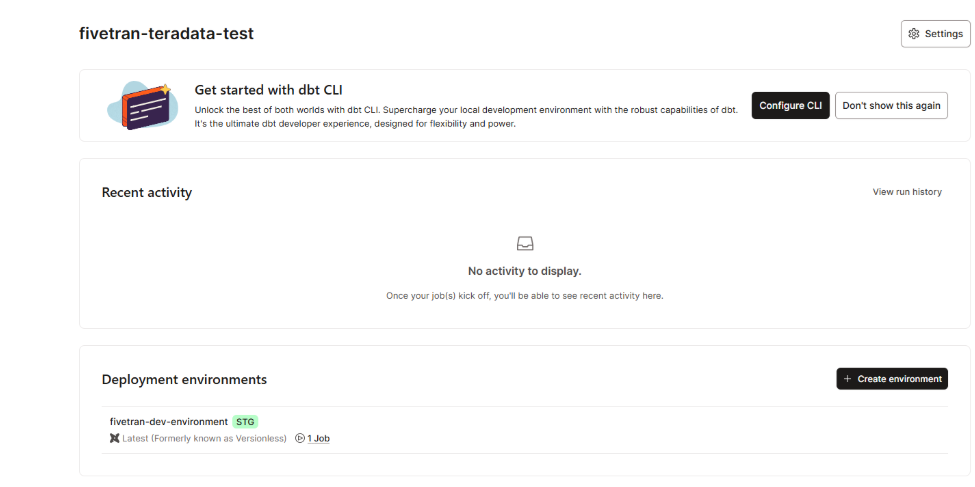
- In the console, select your deployment environment and select
Create job, thenDeploy job
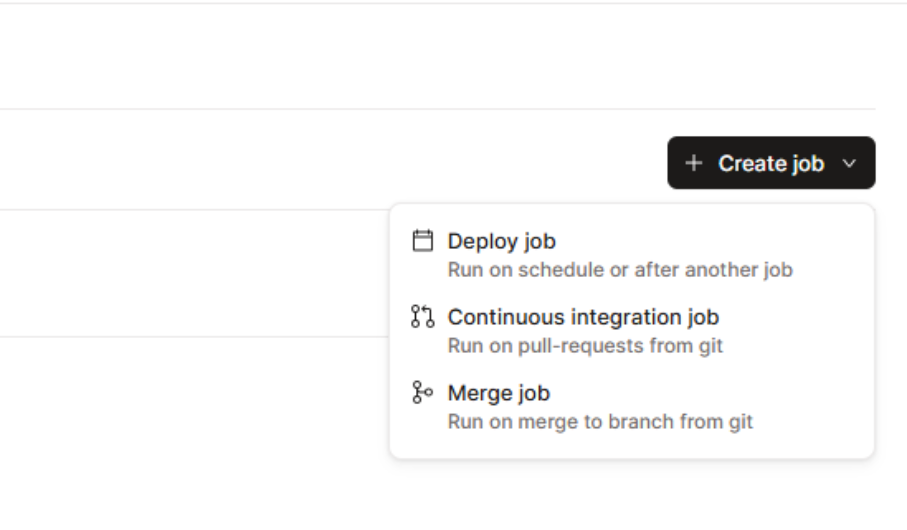
- We keep the job configuration simple by keeping all the defaults; the schedule will be kept in Fivetran
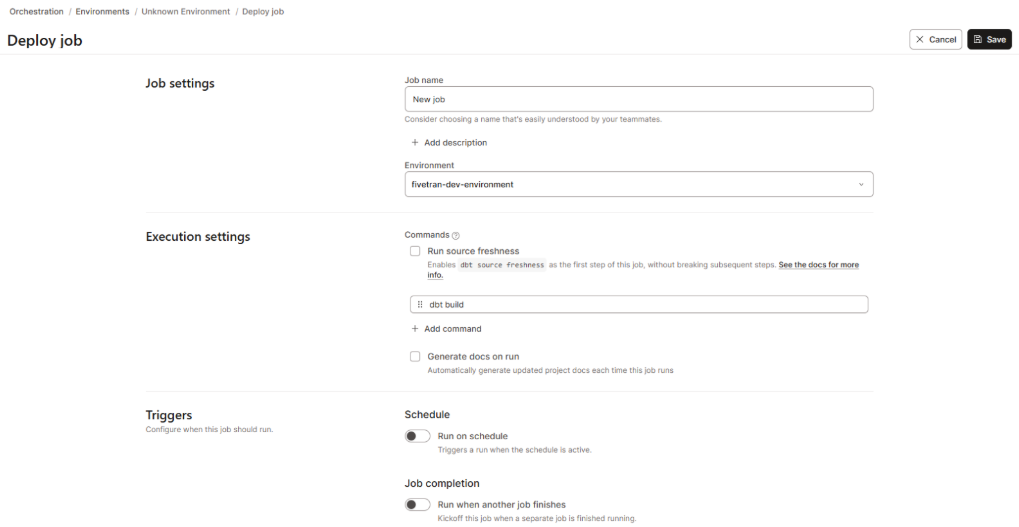
- Save
Building an end-to-end managed data pipeline in Fivetran
- Log in to your Fivetran account
- In the Fivetran console, identify three sections. These sections match the components of the data pipeline:
- Connections, representing data sources
- Destinations
- Transformations
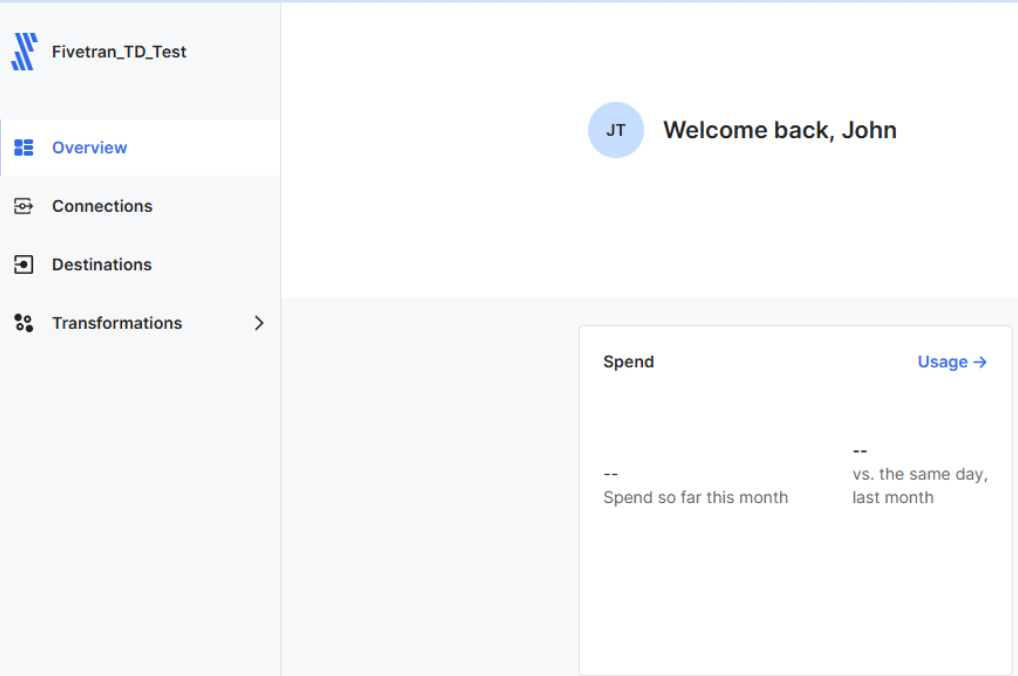
To set up our managed data pipeline, we’ll define a destination (the Teradata Vantage™ instance of our ClearScape Analytics® Experience environment), a set of connections to the spreadsheets in our Google Drive folder, and a transformation, our dbt project.
- Set Teradata Vantage™ as a destination on Fivetran
Destinations are at the heart of Fivetran. Whether it's setting up connections or integrating transformations, the first question Fivetran asks is: What’s the relevant destination? So, our first step is to set that up:
- In
Destinations, selectAdd destination, select Teradata, and provide a name for the connection
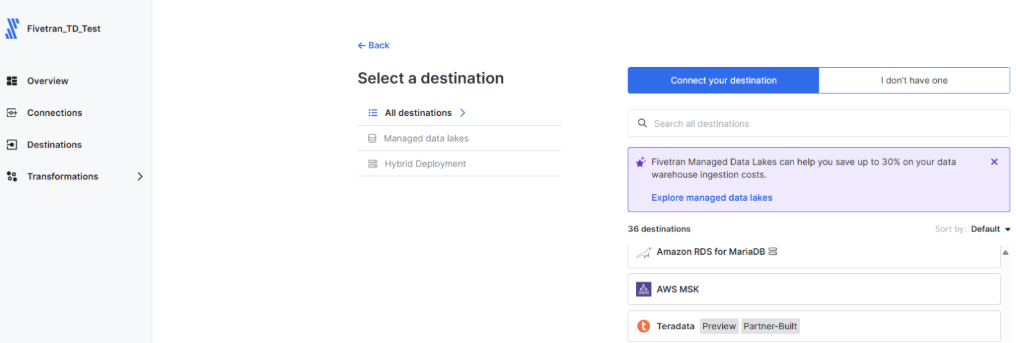
- Enter the credentials for your ClearScape Analytics® Experience environment
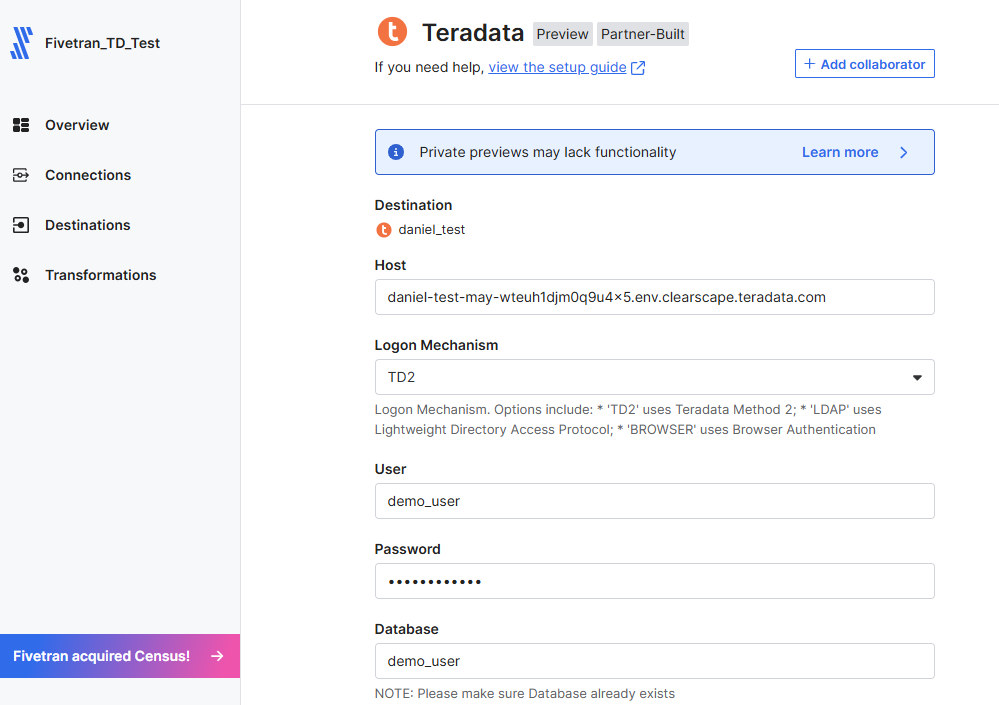
- Save and test your connection
With the destination established, establish connections to your data sources:
- Configuring the data sources as Fivetran connections:
- In connections, select
Add connectionand select Google Sheets - Select your added Teradata destination in the dialog box
- In connections, select
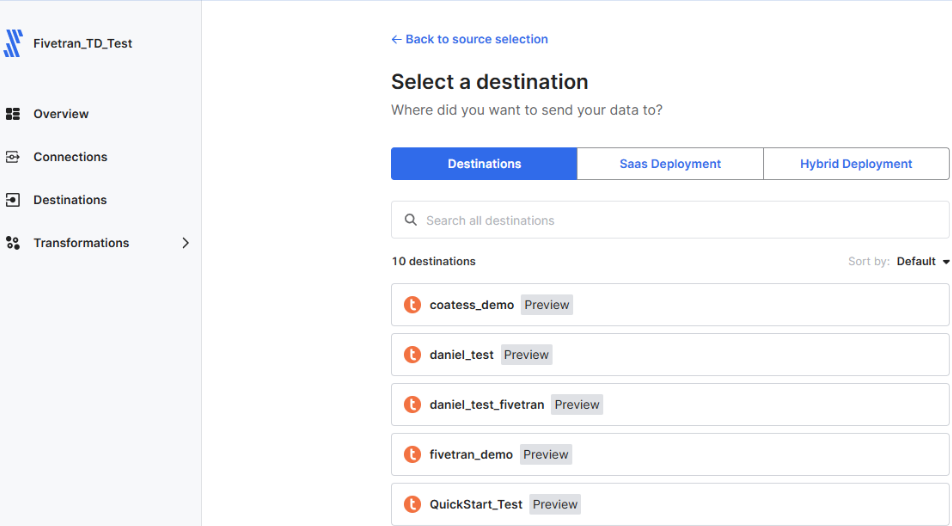
- Since we’re using the Google Sheets connector, we must set each spreadsheet independently; the process is the same for all of them
- The data sources should be configured to match the source definitions in the corresponding dbt project, so set the schema for all the sources as
google_sheetsand the destination tables as follows:
|
Source spreadsheet |
Table name |
|
users |
ecom_users |
|
products |
ecom_products |
|
purchases |
ecom_purchases |
- Authorization is straightforward: You can give Fivetran access to your Google Drive or share specific spreadsheets with the Fivetran service account (note that sharing with view access is enough)
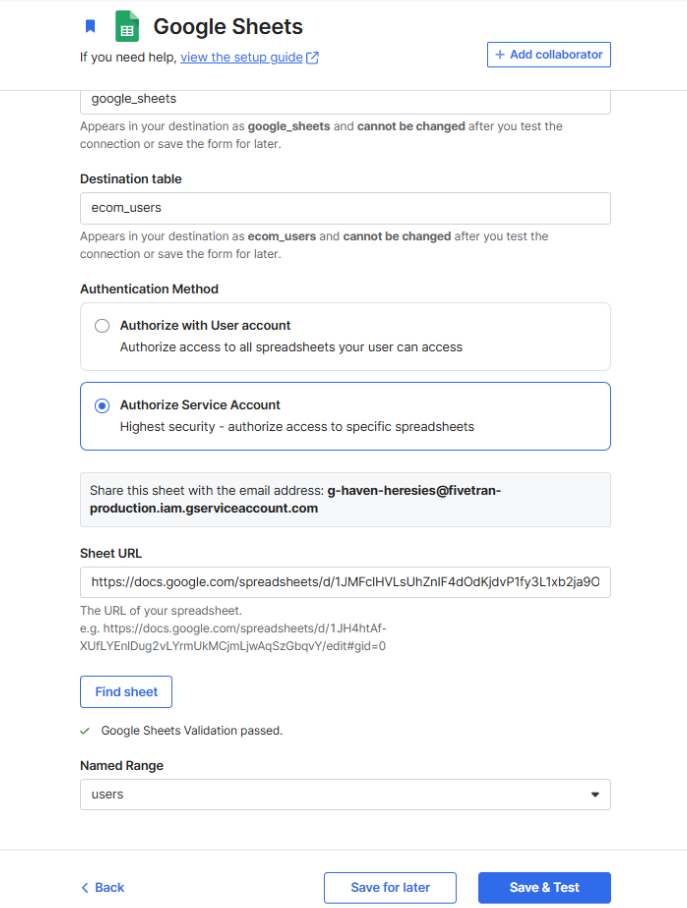
- Save and test the connection
- Repeat for each of the source spreadsheets, taking care to name the schemas and destination tables as defined above
- By default, the connection syncs every six hours
The sources will sync every six hours. Now we’ll integrate the transformation engine with its own schedule.
- Integrate dbt Cloud with Fivetran
- In transformations, select
Connect to dbt Cloud- Fivetran will ask for the destination; choose your Teradata destination
- You’ll need the following data from your dbt Cloud account:
- The
Access URL - The
Discovery API URL - A
Personal Service Token
- The
- In transformations, select
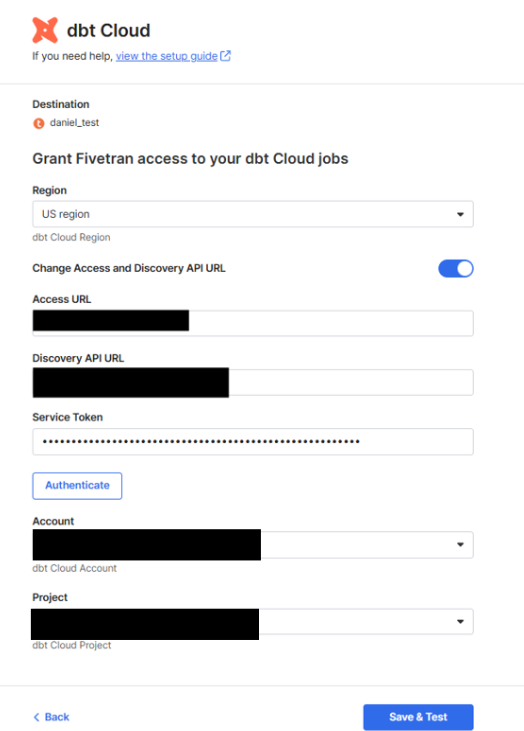
All this data is available through your dbt Cloud account. Depending on your setup, you may need assistance from your dbt Cloud administrator to access some of it.
- Once the transformation is integrated, you can select
Add transformationsand then dbt Cloud
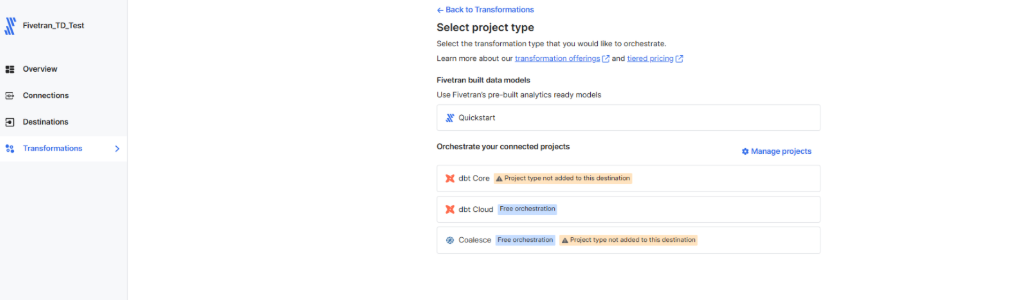
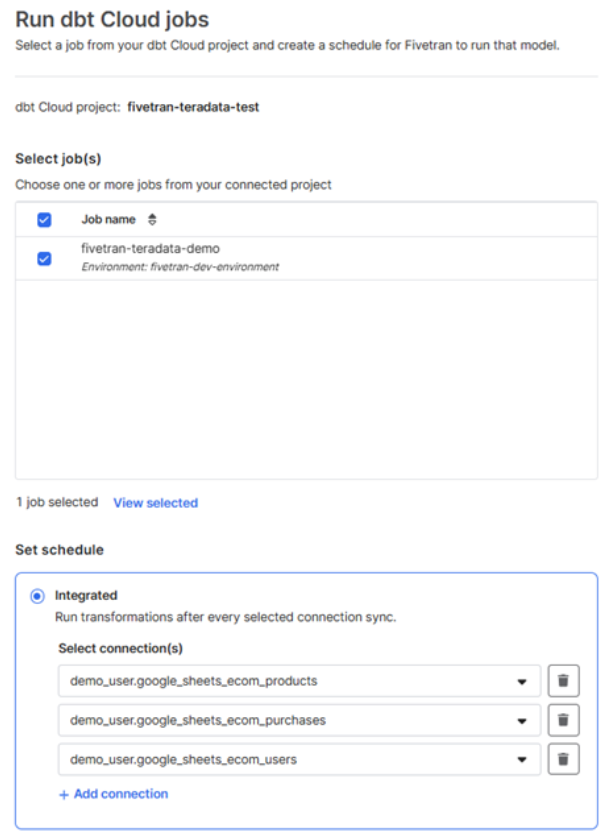
- Your integrated dbt Cloud project will display, highlighting the job we’ve already defined:
- Select that job
- The job will be triggered either on a schedule or when selected connections are synced; this is the use case we’ll implement
- We choose all our connections, since our dbt project depends on all of them
- The connections will synchronize
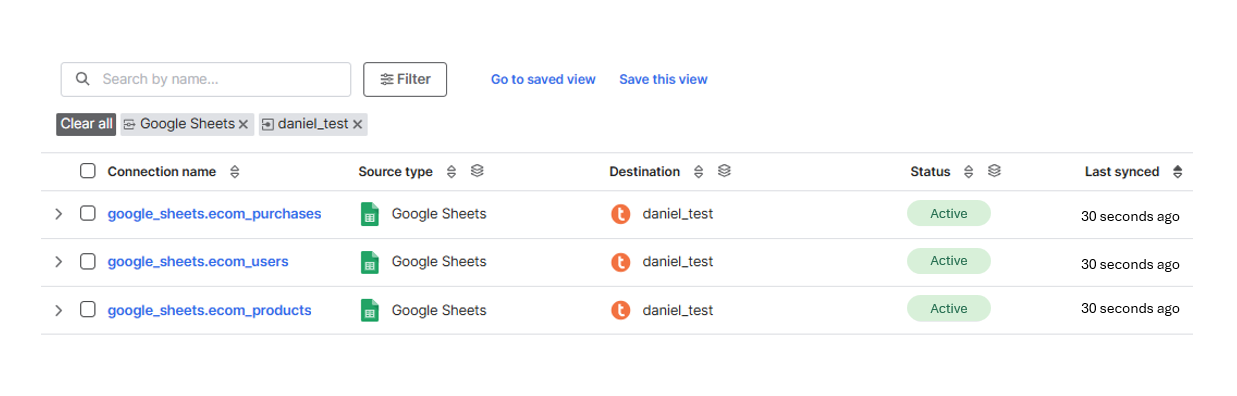
- When the connections synchronize the dbt Cloud job will trigger

- The models will be built
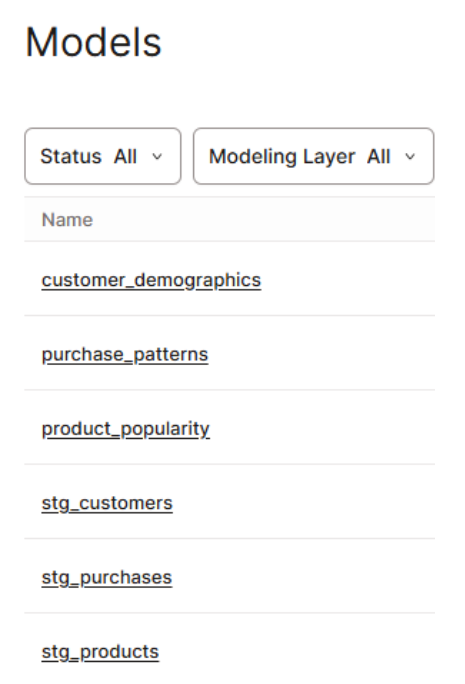
We’ve now built a fully managed data pipeline using Fivetran, dbt Cloud, and Teradata Vantage™. With these three tools, you can design more complex pipelines tailored to your needs. Teradata Vantage™ also provides top-tier performance and a comprehensive set of tools to support your AI/ML initiatives. See it for yourself in ClearScape Analytics® Experience.
Have questions? Reach out through the Teradata developer community or LinkedIn.
To learn more about building data pipelines with Teradata, check out: