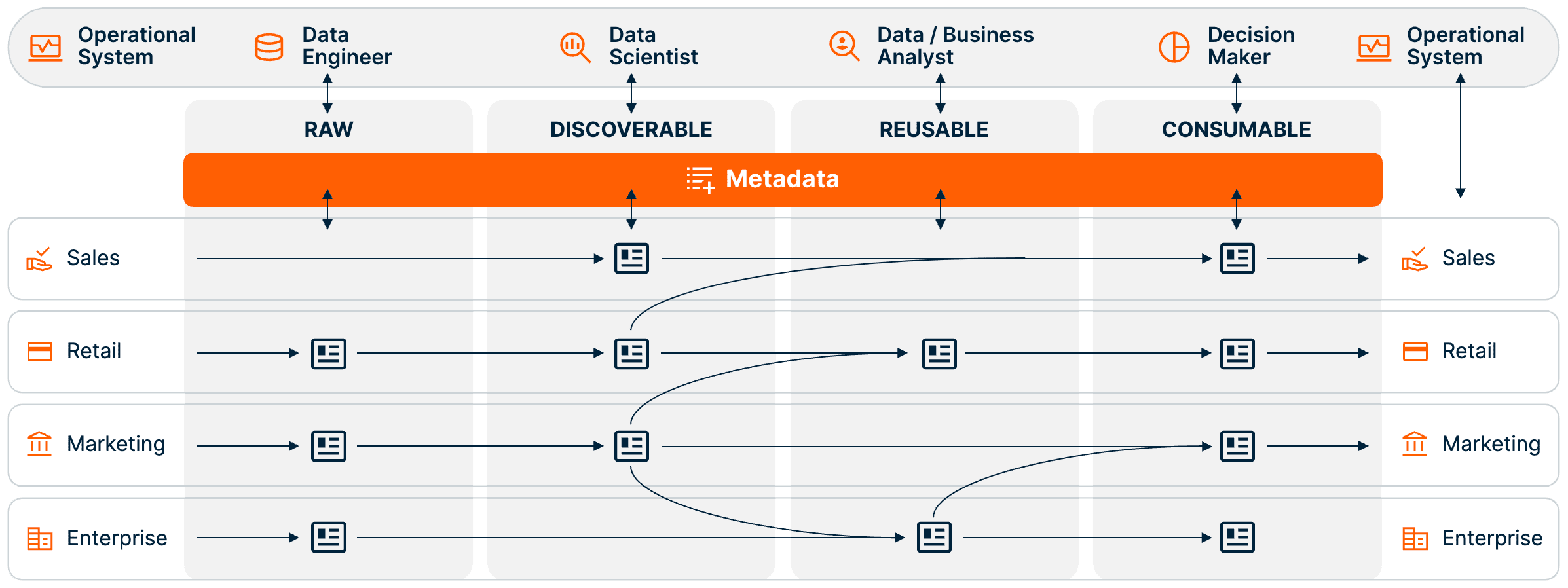
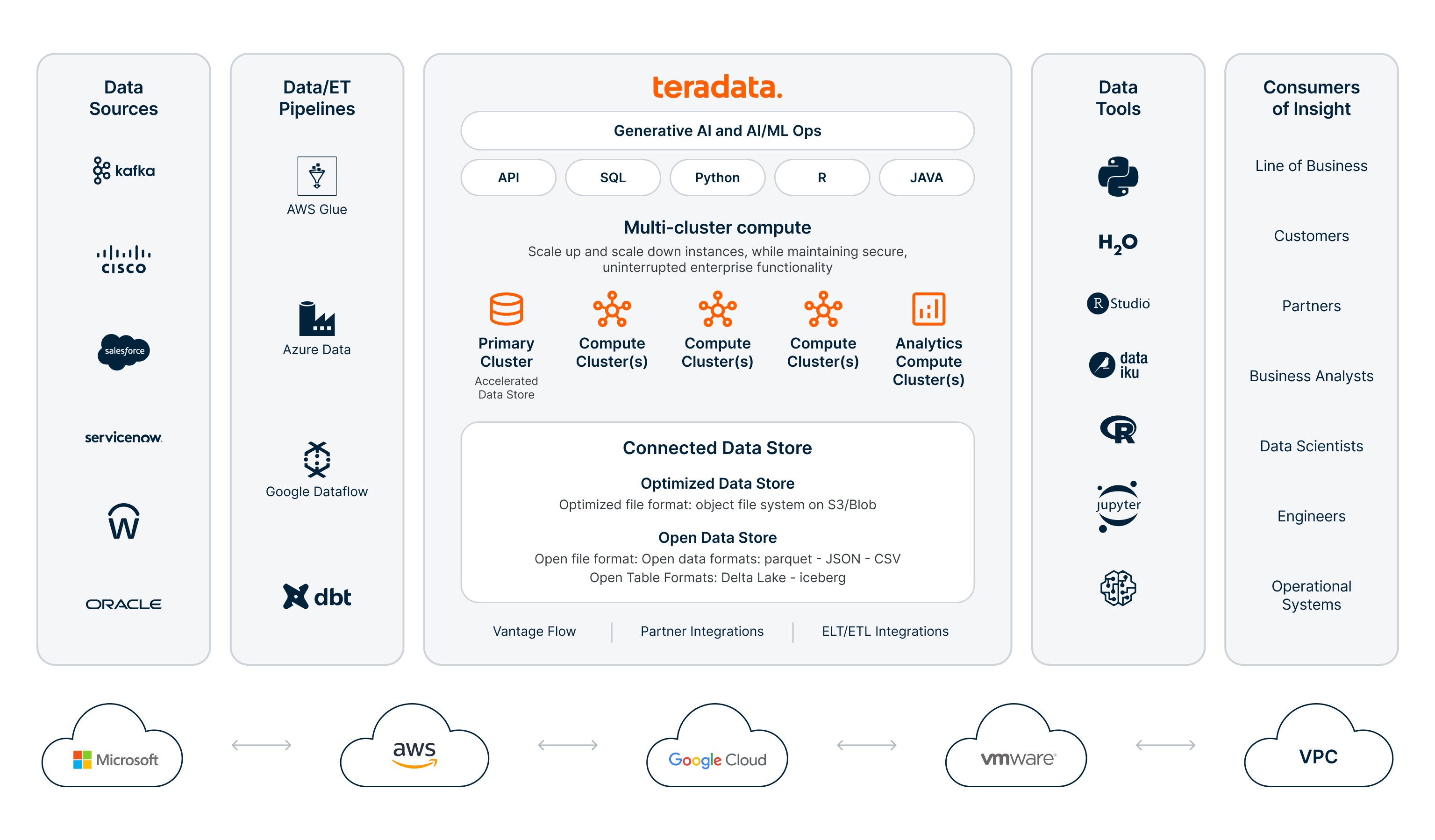
web
Easy to use and flexible
Teradata includes an intuitive web-based console that enables rapid provisioning and the flexibility to execute all types of analytic AI/ML workloads, empowering users to leverage advanced analytics to drive decision-making and innovation.