
Introduction
Operationalizing AI in a secure, on-premises environment comes with its own set of challenges, especially when the goal is to build production-ready applications that handle sensitive, high-volume, or unstructured data.
For a data scientist, that might mean testing large language models against internal documents. For a Machine Learning engineer, it could involve deploying and scaling models efficiently across GPU resources. A data engineer may be focused on integrating structured and unstructured data into unified pipelines, while an AI architect is looking for a system that supports end-to-end control, compliance, and performance at scale.
Teradata and NVIDIA enable AI factories that support all these needs with integrated tools for model development, governance, inference, and vector storage, all working together within your trusted infrastructure.
For a more detailed overview of how Teradata enables AI factories with NVIDIA, explore this article.
In this article, we walk through how it works, from accessing Teradata AI Workbench and deploying a foundation model, to running GPU-accelerated inference and building a RAG pipeline using a PDF document.
How Teradata Enables AI Factories
Automating the full claims lifecycle from document extraction to settlement without human intervention. Monitoring conversations in real time to detect compliance risks before they escalate. Enhancing Anti-Money Laundering detection by bringing together structured records and unstructured sources like social media.
These are just a few of the practical, high-impact solutions developers can build with Teradata.
With integrated vector storage, GPU-accelerated inference, ClearScape Analytics®, and a full-featured AI Workbench, Teradata turns these complex workloads into secure, scalable, and executable pipelines entirely within your own infrastructure.
Let’s take a look at how you can leverage Teradata and NVIDIA for your AI factory.
Accessing the Teradata AI Workbench
Your journey begins at the Teradata AI Workbench landing page, your central hub for everything AI. From here, you can launch notebooks, utilize ModelOps, manage users, and access support if needed, all from a single interface.
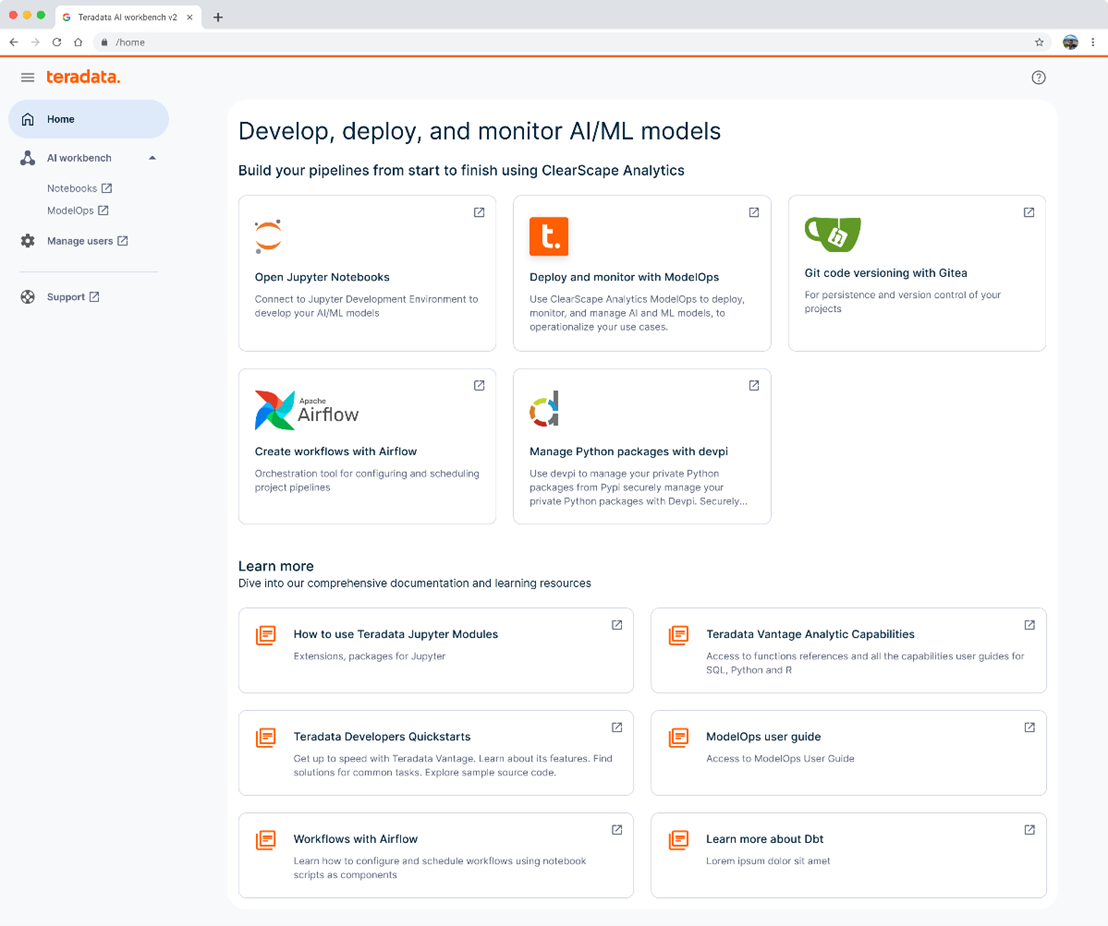 Teradata AI Workbench landing page
Teradata AI Workbench landing page
Exploring ModelOps for advanced AI management
Inside the Workbench, ModelOps provides a complete environment for managing your AI models, including access to NVIDIA NIM microservices and a collection of over 80+ pre-trained Large Language Models (LLMs), all ready to be deployed on your GPUs using NIM.
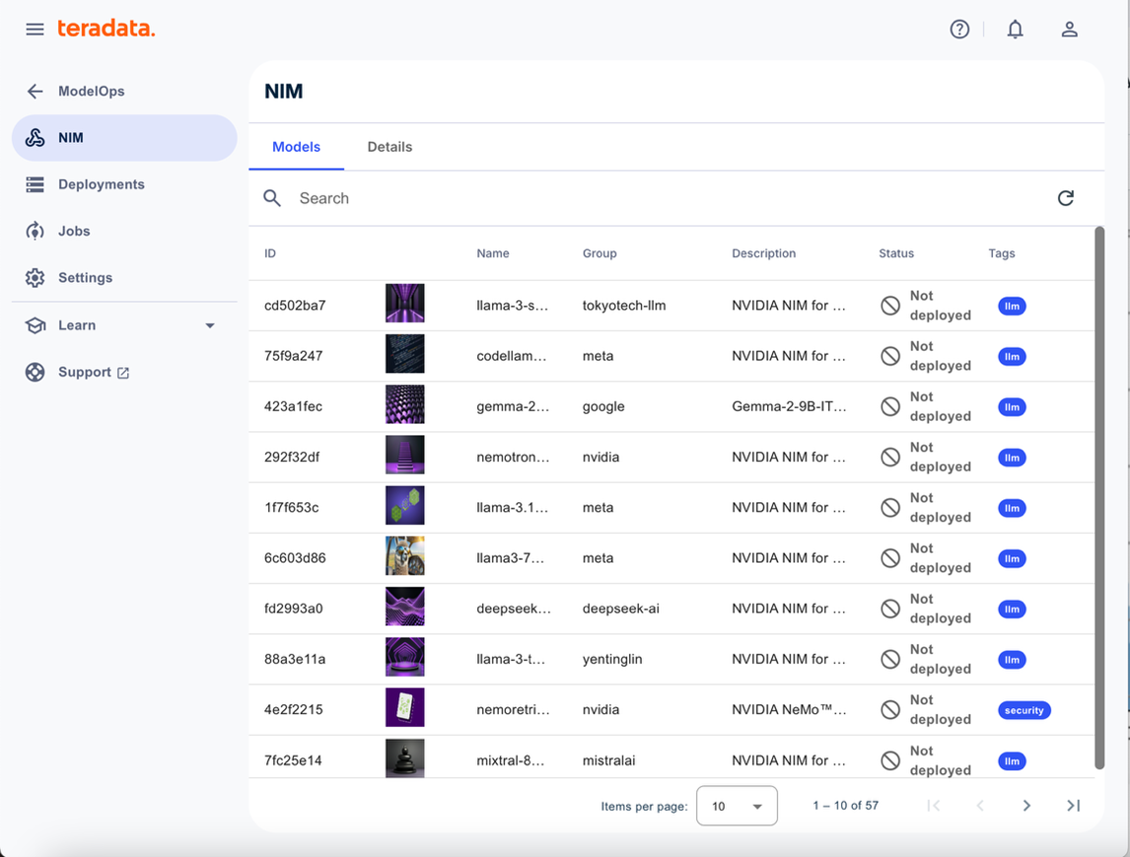
List of AI Foundation Models in Teradata AI Workbench
Selecting a model
Selecting a model is as simple as a click. Choose any NIM, and a model card will open with details such as model evaluation, benchmark performance, license information, and resource profile.
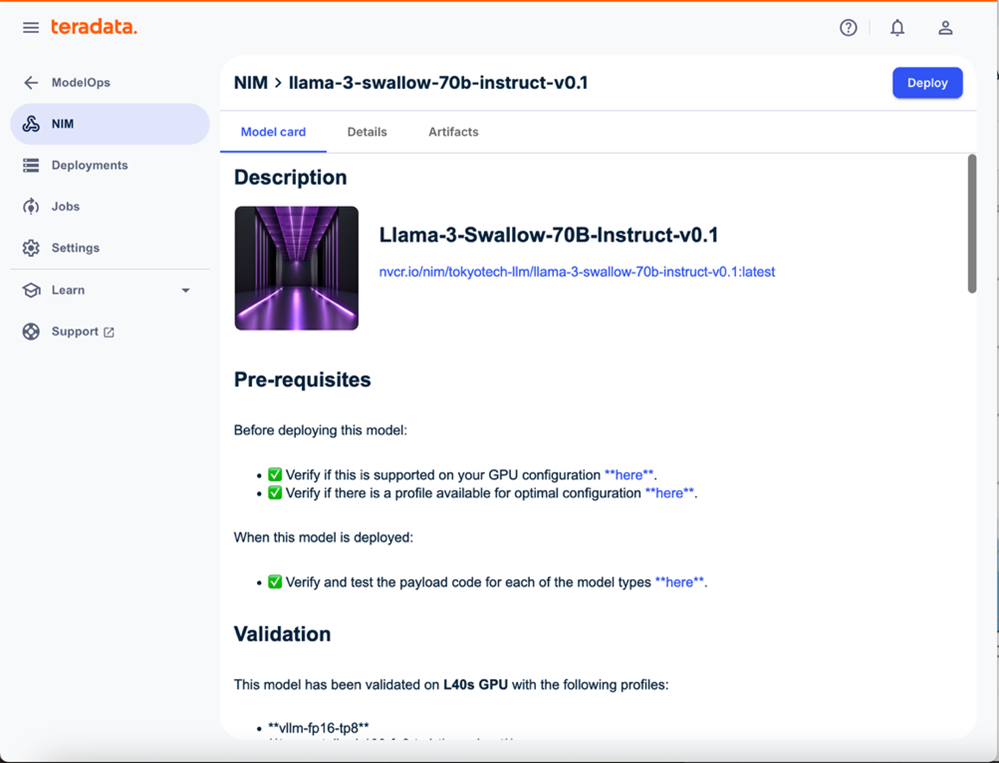
Model card for Llama-3-Swallow-70B Instruct v0.1
One-click model deployment
After reviewing a model, you can deploy it with just one click. Once deployed, you receive an endpoint and a code snippet, perfect for integrating the model into your Generative AI applications, including Retrieval-Augmented Generation (RAG) workflows with Teradata Enterprise Vector Store.
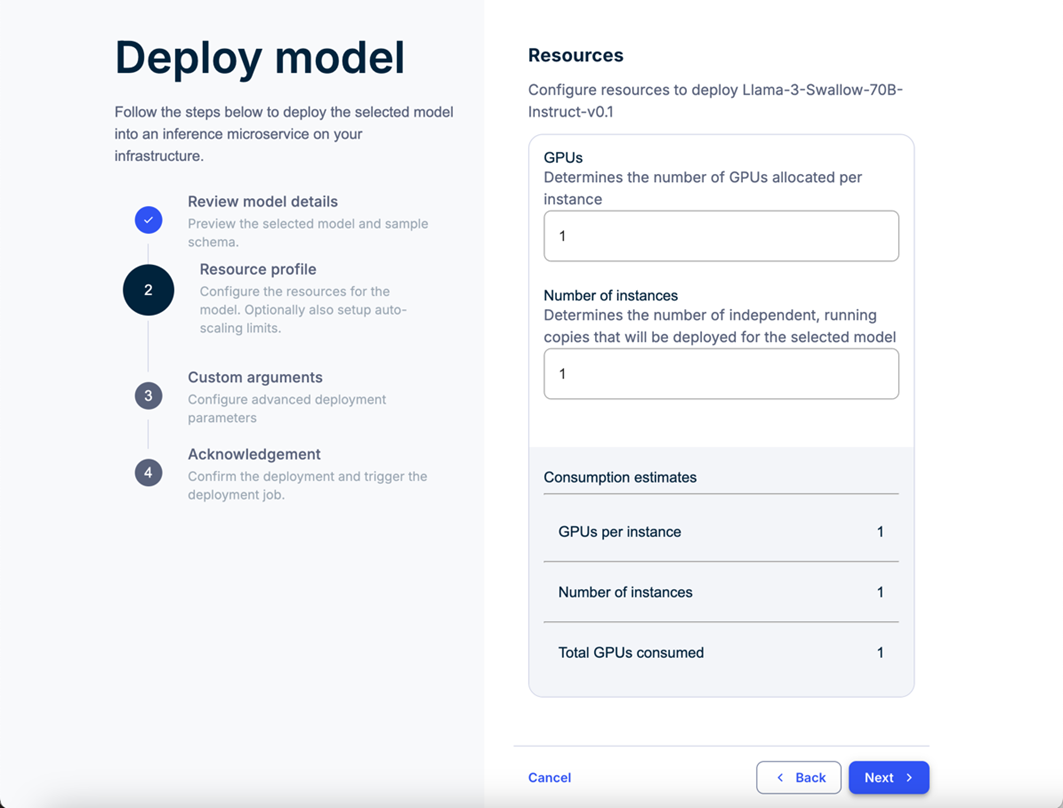
Model deployment steps in Teradata AI Workbench
Running inferences and building applications
With your model deployed and the endpoint ready, you can immediately start running inferences against your data. This enables you to quickly build applications for demonstration, experimentation, or even production use cases.
A practical use case: PDF Vector Store with RAG
One of the standout capabilities is its ability to transform unstructured documents into actionable insights using RAG.
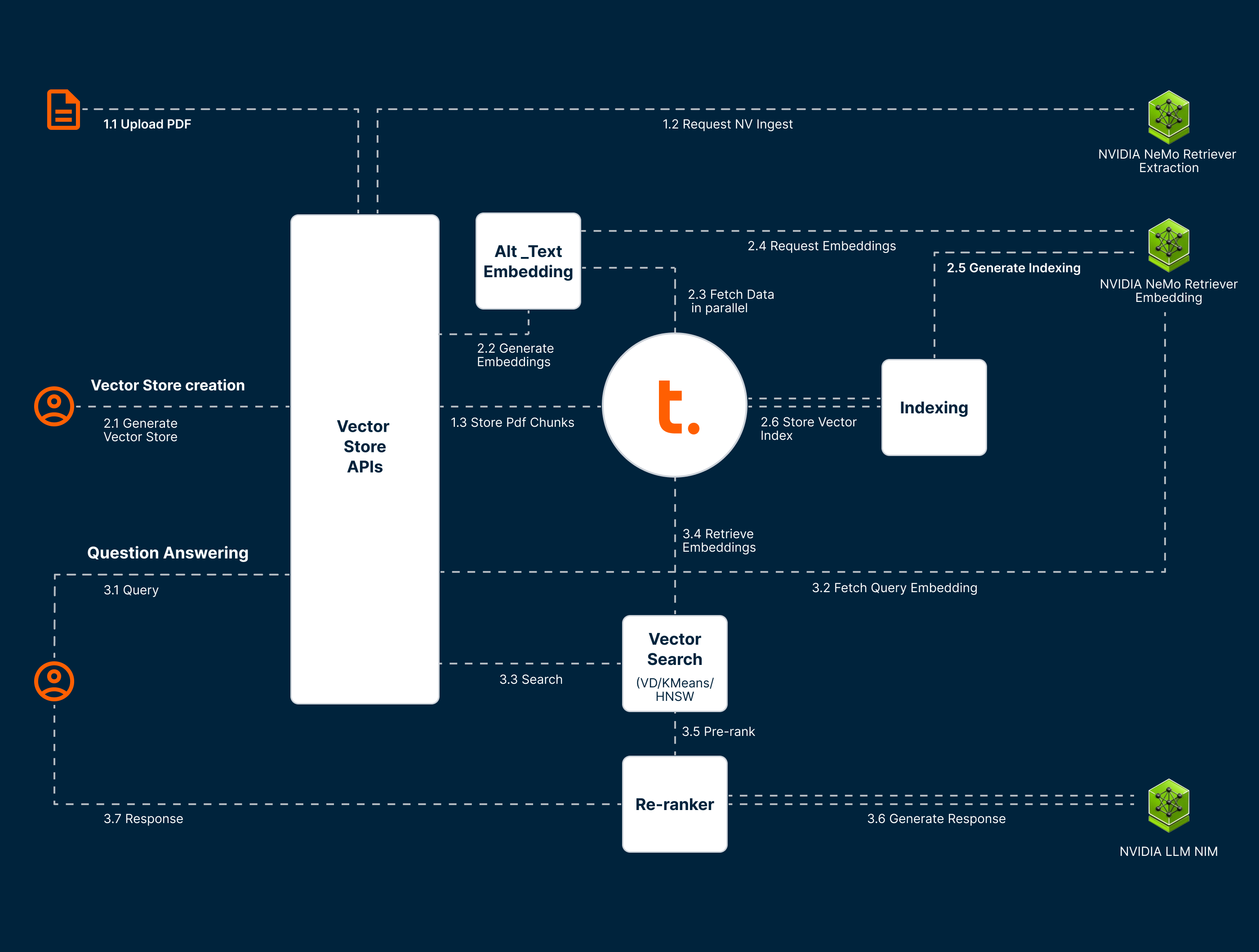
Teradata implementation for AI Factories
Teradata AI Microservices with NVIDIA enables access to GPU-accelerated tools for processing PDFs, extracting text, images, tables, and charts using OCR, object detection, and table parsing. These documents are then enriched using NVIDIA NIM to generate high-dimensional vector embeddings via contextual LLMs.
Finally, the embeddings are indexed in Teradata’s Enterprise Vector Store, enabling fast, intelligent search across the data. This pipeline makes it easy to build RAG applications that can analyze, summarize, and surface relevant insights from unstructured documents—quickly and securely.
Code example: building a Vector Store with an NVIDIA model
Let’s walk through how to create a vector store and ask contextual questions using a PDF document. In this example, we’re using a sample file named data_access_policy.pdf to demonstrate the steps. You can replace it with your own document as needed.
Install and import required modulesInstall the teradatagenai module, a Teradata package for Generative AI and import the required classes.
!pip install teradatagenai
from teradatagenai import VSManager, VectorStore, VSPattern, VSApi
import os
Create an instance of the vector store named “vs_chatbot”
chatbot = VectorStore('vs_chatbot')
You can also check the system health to know if your system is running fine or not with “VSManager.health()”.
Load the document and define the embedding model
Load a sample PDF and specify the NVIDIA embedding model (nv-embedqa-mistral-7b-v2).
files = [os.path.join(os.getcwd(), "data_access_policy.pdf")]
embeddings_model = 'nvidia/nv-embedqa-mistral-7b-v2'
nv-embedqa-mistral-7b-v2 is a multilingual text question-answering retrieval model from NVIDIA.

data_access_policy.pdf content
Generate the vector embeddings for the document and store them using Teradata’s Enterprise Vector Store.
chatbot.create(embeddings_model=embeddings_model,
search_algorithm= 'VECTORDISTANCE',
top_k= 10,
object_names= ['data_access_policy'],
data_columns= ['chunks'],
vector_column= 'VectorIndex',
chunk_size= 500,
optimized_chunking=False,
document_files=files)
Confirm if the vector store is ready for querying.
chatbot.status()
You can query the vector store with a business-specific question using ask method. The vector store will use its similarity search to find the most relevant information and provide a detailed response.
question = 'What are the levels of access to patient data allowed in our organization?'
prompt = 'List the levels of access and briefly describe them.'
response = chatbot.ask(question=question, prompt=prompt)
print(response)

Output of ask method
This response was generated directly from the uploaded PDF using the ask() function in Teradata AI Factory. It shows how unstructured documents can be converted into actionable insights accurately, securely, and instantly.
Conclusion
Teradata and NVIDIA provide everything needed to build, deploy, and manage AI workloads entirely on-premises by combining model development, GPU-powered inference, vector management, and workflow automation into a single integrated environment.
AI factories leveraging Teradata and NVIDIA equip data scientists, machine learning engineers, data engineers, and AI architects with the tools to experiment, scale, and operationalize AI, all while maintaining full control over performance, compliance, and data security.
To learn more about AI factories leveraging Teradata and NVIDIA, explore here.