

In this article, we'll explore how to build a data mesh architecture using Teradata VantageCloud Lake as the core data platform on Amazon Web Services (AWS). This architecture empowers teams to own and manage their data domains independently, enhancing scalability, agility, and autonomy within the organization.
Introduction to Teradata VantageCloud Lake on AWS
Teradata VantageCloud Lake, a comprehensive data platform, serves as the foundation for our data mesh architecture on AWS. VantageCloud Lake provides robust capabilities for data storage, parallel processing, and analytics, making it an ideal choice for building scalable and performant data solutions.
The data mesh architecture
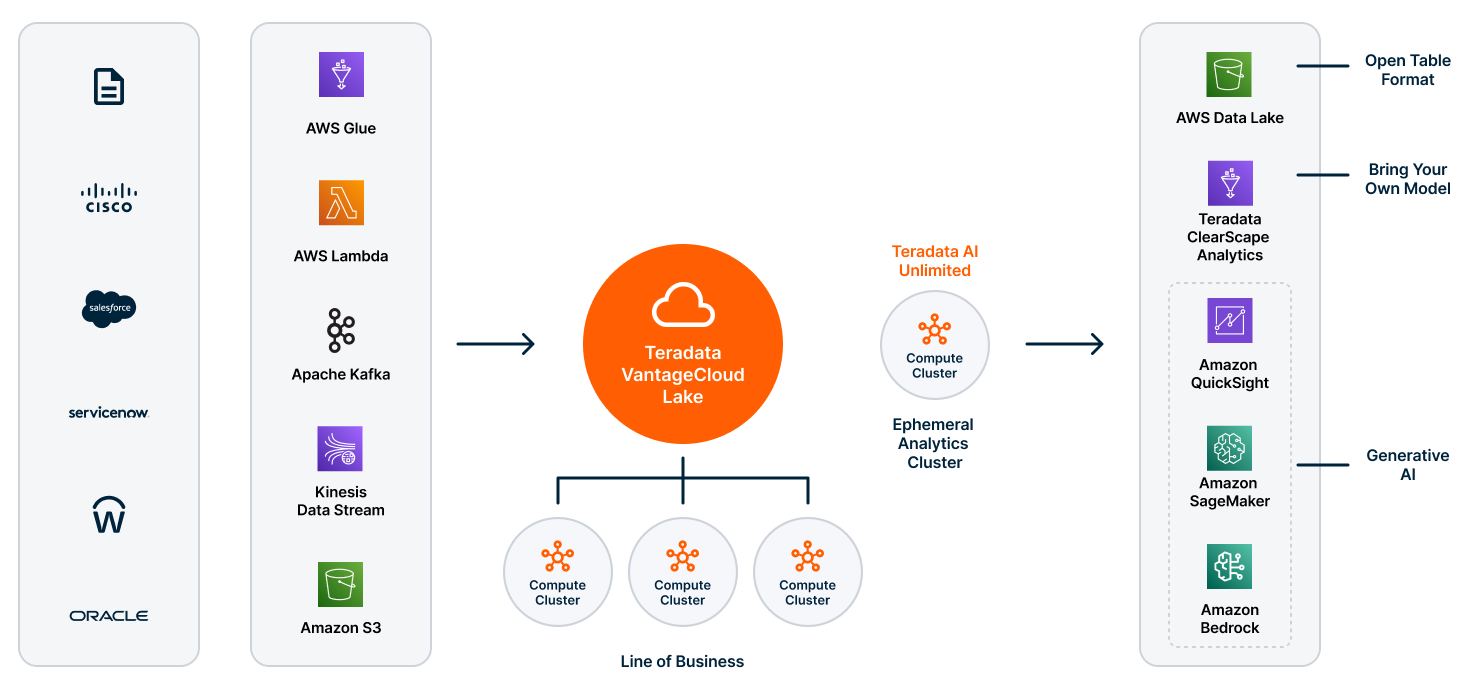
Key components of the data mesh architecture
1. Data domains
In the data mesh architecture, data domains represent distinct business areas or use cases within an organization. Each data domain is owned and managed by a dedicated team responsible for its data quality, governance, and accessibility.
Data domains within VantageCloud Lake leverage the platform's robust compute cluster capability for efficient workload management and resource allocation. The compute clusters in VantageCloud Lake establish natural boundaries between different types of workloads, allowing tasks from specific departments or applications to be isolated on dedicated compute clusters. This isolation eliminates the need for complex workload management rules, as workloads are processed independently within their respective clusters. Additionally, departments have control over their resource consumption and costs through compute groups, which enable custom resource allocations and throttle rules. This is further enhanced by the built-in role-based access control (RBAC) and detailed object security features of the database, which provide isolation from both a workload and security/access perspective. These security measures ensure that only authorized users have access to specific data and resources, maintaining strict governance and compliance across the organization.
The auto-scaling capabilities within compute clusters dynamically adjust resource provisioning based on workload demands, ensuring optimal resource utilization throughout the day. This emphasis on simplicity and ease of use in workload management simplifies operations and minimizes complexity.
Teradata Block File System (BFS) enhances data domain isolation by providing a high-performance, scalable storage solution that supports efficient data management and retrieval. This system ensures that data is stored in a structured manner, facilitating quick access and processing while maintaining data integrity and security.
Teradata Object File System (OFS) contributes to data domain integration by offering an optimized storage environment designed for performance. It leverages a columnar format within an object storage system, enabling high-speed data retrieval and efficient storage management. This system supports workloads that demand quick access and processing, ensuring seamless integration across different data domains.
Open table format (OTF) provides a flexible, cost-efficient storage abstraction layer that simplifies data management. It enables cross-read, cross-write, and cross-query capabilities across various data sources, reducing the need for data movement and replication. This approach ensures that data remains synchronized and accessible, promoting interoperability and cost efficiency.
By leveraging VantageCloud Lake's compute cluster capability, along with the benefits of BFS, Object File System (OFS), and OTF, data domains can efficiently manage their workloads, optimize resource utilization, and ensure seamless processing of departmental or application-specific tasks within the data mesh architecture.
2. AI/ML lab
In addition to establishing data domains, our data mesh architecture includes an AI/ML lab that empowers teams to independently run machine learning experiments, deploy pre-built models, and import custom standard or large language models (LLMs) into the platform. Teradata services such as ClearScape Analytics™ and AI Unlimited provide the necessary capabilities for teams to leverage advanced analytics, machine learning models, and custom language models within their respective domains.
Teams within the AI/ML lab can perform the following tasks autonomously:
- Machine learning experimentation: Teams can explore and experiment with machine learning algorithms and models tailored to their specific business needs
- Model deployment: Once machine learning models are trained and validated, teams can deploy them seamlessly within their domain using VantageCloud Lake's ClearScape Analytics services
To further simplify and democratize cloud analytics within the AI/ML Lab, ask.ai, a generative AI capability within VantageCloud Lake, offers faster innovation and decision-making capabilities using natural language. This feature empowers business users and analysts, even those without technical expertise in data science or machine learning, to easily interact with the system.
With ask.ai, teams can:
- Generate code for various tasks, such as data manipulation and model training
- Explore analytics features and functions usage
- Query system information effortlessly
By leveraging ask.ai, AI/ML labs can enhance collaboration, boost productivity, and accelerate the development of impactful solutions.
3. Platform domain
AWS serves as the underlying platform for hosting our data mesh architecture with VantageCloud Lake, leveraging a suite of services to enable scalable data storage, compute, streaming, and extract, transform, and load (ETL) capabilities. Key services include Amazon S3 for scalable and durable object storage that powers Teradata NOS, Teradata OFS , Amazon EC2 for scalable compute capacity, Amazon Athena for serverless querying and federation capabilities on multiple datastores, including Teradata, Amazon MSK, Amazon Kinesis for scalable and reliable streaming data processing, and AWS Glue for data integration and ETL operations. These platform services complement VantageCloud Lake's capabilities, allowing organizations to build scalable, performant, and efficient data solutions within the data mesh architecture on AWS.
Self-service capabilities are a key aspect of the platform architecture, enabling teams to easily provision clusters and compute resources through a user-friendly console available with VantageCloud Lake. This self-service approach empowers teams to quickly and efficiently manage their infrastructure needs without relying on centralized IT support, fostering agility and innovation within the organization.
4. Data access domain
The data access layer in our data mesh architecture enables efficient data access and querying through data federation and programmatic access methods.
Data federation
Data federation is achieved through a combination of services that facilitate unified querying across disparate data sources:
- Amazon Athena offers serverless federation querying capabilities for AWS data lake and other data stores, such as Teradata. It supports standard SQL queries and enables ad-hoc analysis directly on data in Amazon S3 without the need for complex ETL processes. Teams can leverage Athena to perform interactive queries and join operations across datasets stored in the data mesh.
- QueryGrid™ facilitates seamless data access and integration by enabling federated queries across multiple data platforms. QueryGrid allows teams to execute SQL queries that span VantageCloud Lake, relational databases, Hadoop, and other cloud-based data stores. This capability enables real-time insights by combining queries across different data sources with minimal data movement and pushdown processing. With pushdown processing, QueryGrid executes parts of the query directly on the source systems, minimizing data movement and improving efficiency.
- In addition to data federation, the data access layer supports various programmatic access methods for interacting with domain data products (DDPs) and datasets within the data mesh. By focusing on consumable data products, it ensures easy and efficient access, enabling users to derive insights and make decisions quickly.

- Teams can develop RESTful APIs to expose domain data products securely and enable controlled access to specific datasets.
- Programmatic SQL access allows for automation and integration of data queries into applications and workflows.
- Data analysts and data scientists can use Python, R, or Java scripts to interact with data stored in the data mesh, leveraging libraries and tools for data manipulation, analysis, and visualization.
Implementing the data mesh architecture on AWS
Now, let's delve into the steps for implementing our data mesh architecture using VantageCloud Lake on AWS:
- Define data domains: Identify and define distinct data domains based on business functions or use cases within your organization
- Establish domain teams: Form dedicated teams for each data domain, comprising domain experts responsible for data governance and operations
- Deploy VantageCloud Lake on AWS: Set up VantageCloud Lake SaaS infrastructure on AWS through the AWS Marketplace
- Integrate platform services: Leverage AWS services like Amazon Kinesis and Amazon Glue to extract, load, and transform data and integrate VantageCloud Lake with data federation services and programmatic access methods within the data access layer
- Implement data access layer: Leverage ClearScape Analytics capabilities to interact with your data via programming languages and federated query applications, such as Amazon Athena, and leverage APIs to integrate your application
Benefits of the data mesh architecture
Building a data mesh architecture using VantageCloud Lake on AWS offers several benefits:
- Scalability: Teams can independently scale their data domains and infrastructure based on evolving business needs
- Autonomy and agility: Empowers domain teams to own end-to-end data lifecycle management, fostering agility and innovation
- Data governance: Centralizes data governance and access controls while allowing decentralized ownership and management of data domains
- Performance: Leverages VantageCloud Lake's high-performance analytics engine alongside AWS services for optimal data processing and analysis
- Fast AI/ML experimentation and productization
By adopting a data mesh architecture using VantageCloud Lake on AWS, organizations can achieve greater scalability, autonomy, and efficiency in managing their data assets. This approach promotes agility and collaboration across teams while ensuring robust governance and performance of data-driven initiatives.